ImportOSM
Z UMP
Spis treści |
Założenia (prawne)
stara licencja OSM
Osoby wkładają swoją wiedzę do OSM, i zgadzają się na użycie licencji OSM (czyli obecnie CC-BY-SA), ale nadal są tej wiedzy właścicielami. UMP może
- dostać te dane jeszcze raz od danej osoby, wtedy po raz drugi wiedza danej osoby, oraz realizacja przez edytora UMP, jest obejmowana licencją UMP (także CC-BY-SA)
- wziąć te dane bezpośrednio z OSM, opisując obiekty stosownie do licencji OSM.
nowa licencja OSM
?
dyskusje
Na Flyspray oraz na forum OSM.
Sposób z użyciem skryptu Perl osm2mp.pl
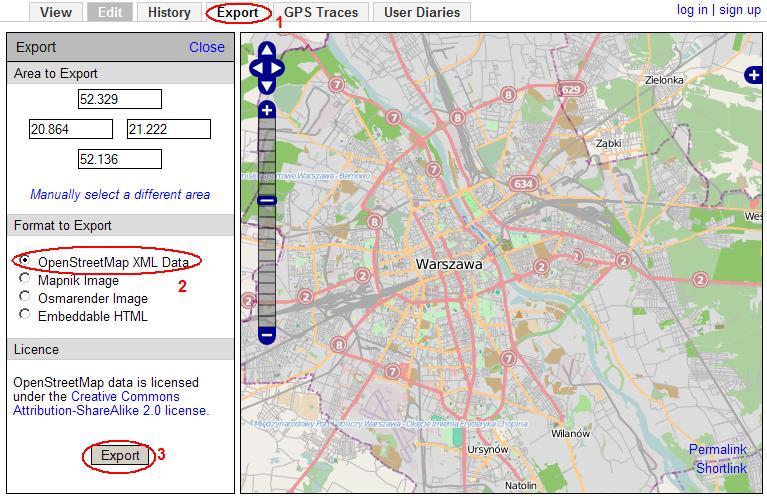
- Ściągnąć dane w formacie XML *.osm
- Najłatwiej tego dokonać z użyciem przeglądarki WWW. Wchodzimy na stronę OSM
- Wybieramy obszar który na interesuje. Maksymalny dowolny rozmiar to kwadrat kilkadziesiąt kilometrów. Zoom level >=11.
- Teraz na górze zakładka Export, dalej 'Format to Export' -> 'OpenStreetMap XML Data' i przycisk 'Export'

- Alternatywnie -- eksporty *.osm dla krajów Europy generowane codziennie leżą tutaj -- zamiast generować samodzielnie wystarczy ściągnąć cały obszar, ew. przyciąć go potem odpowiednimi narzędziami do interesującego obszaru.
- Konwersja *.osm -> *.mp
Należy ściągnąć skrypt perlowy osm2mp.pl z http://code.google.com/p/osm2mp/ (starsze wersje -- z forum OSM) Strona poświęcona konwerterowi osm2mp.pl http://wiki.openstreetmap.org/wiki/Osm2mp, historia zmian na Code Google
Uwaga: Przerobiłem osm2mp.pl tak żeby: * Umożliwiał odsianie obiektów zaimportowanych od nas ( opcja --umpremove ) * Wstawia do komentarza dowolny tag z obiektu n.p. ( --xcommentlist="surface" ) * Dodaje automatycznie coś do obiektów n.p. Miasto= lub Plik= Jeśli ktoś potrzebuje mogę wrzucić do narzędzi w CVSie.
Zainstalować Perla wraz z wymaganymi pakietami.
* Template-toolkit * Getopt::Long * Text::Unidecode * List::MoreUtils * Math::Geometry::Planar::GPC::Polygon * Math::Polygon::Tree * Math::Polygon * Tree::R * Data::Dump
Na Linuksie każdy sobie poradzi (albo i nie). Najprościej zrobić to z samego perla, pisząc:
# perl -MCPAN -e shell Terminal does not support AddHistory. cpan shell -- CPAN exploration and modules installation (v1.9402) Enter 'h' for help.
cpan[1]> install Math::Geometry::Planar::GPC::Polygon ...
itd. Na Windows działa z ActivePerlem.
Uruchomić konwerter z linii komend z opcjami --norouting --codepage 1250
C:\Garmin\osm2mp>c:\Perl\bin\perl.exe osm2mp.pl --norouting --codepage 1250 map.osm >out.mp
---| OSM -> MP converter 0.80 (c) 2008-2010 liosha, xliosha@gmail.com
Processing file map.osm
Loading nodes... 41943 loaded
Loading relations... 3 multipolygons
0 turn restrictions
0 destination signs
Loading necessary ways... 37 loaded
Processing multipolygons 0 polygons written
0 cities and 0 suburbs loaded
Processing nodes... 229 POIs written
4 barriers loaded
Processing ways... 106 lines and 818 polygons dumped
805 roads loaded
Merging roads... 121 merged
Detecting road nodes... 1121 found
Detecting duplicates... 5 segments, 4 roads
Splitting roads... 11 self-intersections, 0 long roads
Fixing close nodes... 0 pairs fixed
Writing roads... 695 written
Writing crossroads... 8 restrictions, 0 signs
All done!!
Docelowo plik out.mp otwieramy sobie ulubioną wersją edytora MapEdit w jednym okienku, a w drugim uruchomionym MapEdit/ME++ otwieramy interesujący nas obszar UMP-a i kopiujemy lub przenosimy interesujące nas obiekty z jednego ME do drugiego. Zanim to jednak rozpoczniemy, warto wyczyścić mapę OSM z różnych dziwnych rzeczy, które potem będą przeszkadzały w mapie UMP. Lepiej to zrobić globalnie na tej mapie roboczej niż potem pracowicie poprawiać na każdym zaimportowanym elemencie.
Na co uważać przy edycji takich danych:
- Dane z OSM mają czasem i po 20 cyfr po przecinku. Mapedit i Mapedit++ potrafią na takich danych zgłupieć (pierwszy raz otwierają poprawnie, ale zapis mapy (np. po wycięciu części elementów) potrafi bezpowrotnie taką mapę zepsuć). Aby uniknąć problemów, dobrze jest przed jakąkolwiek dalszą obróbką "znormalizować" taką mapę. Komenda "
make norm" pod uniksem robi to na pliku wynik.mp. Można zrobić analogicznie albo kopiując tymczasowo obrabianą mapę do tego właśnie pliku. - Oprócz dróg OSMowe POLYLINEs zawierają także różne dziwne obiekty (np. barrier = 0x1e012), o których warto pamiętać i je usunąć
- Różnego rodzaju niespójności danych OSM konwerter oznacza w jednym miejscu zbitkiem komentarzy typu WARNING, ERROR i FIX. Najlepiej je usunąć bez wnikania w treść (np.
grep -v). - Dane w OSM bywają różne, często zdarza się, że jakaś polna ścieżynka (albo i droga główna) jest wynikiem iportu ze śladu i ma punkty ponastawiane co 1-2 metry albo i gęściej, nawet na prostych odcinkach. Nie dość, że niepotrzebnie komplikuje to mapę, to może powodować błędy kompilacji (zbyt bliskie węzły), dlatego całą mapę przed dalszą obróbką należy poddać procesowi "Generalize nodes". Należy to zrobić ZANIM usuniemy z mapy informacje o węzłach routingu, w przeciwnym razie Mapedit uprości także te węzły, które są skrzyżowaniami.
- Jeśli nie użyjemy opcji --norouting, to po konwersji dostajemy dane z informacjami o routingu. Można z nich wyłuskać zakazy skrętów (skryptem narzedzia/restr_extract), ale trzeba je potem ręcznie weryfikować – OSM często restrykcji używa tam, gdzie my ustawiamy parametrem drogi zakaz wjazdu (czyli restrykcja jest zaczepiona na końcach odcinka drogi i jakimś punkcie w środku plus druga taka sama tylko w przeciwnym kierunku). Wszystkie restrykcje można sprawdzić pisząc "
make x bm mont" i przyglądając się miejscom, gdzie zostały postawione bookmarki wskazujące źle wpasowane restrykcje (oraz inne błędy routingu, np. przecięcia). - Po wyekstrahowaniu restrykcji warto usunąć wszelkie dane o routingu i dopiero taki plik otworzyć w mapedicie i z niego kopiować do UMPa. Mimo usunięcia węzłów routingowych pozostają parametry RouteParam= zawierające m.in. klasy routingu. Chwilowo muszą zostać. ale planowany jest skrypt narzędziowy UMPa, który pousuwa te wpisy, które są zgodne z UMPowymi wartościami domyślnymi (np. zakaz wjazdu dla motorów/samochodów/ciężarowych/itd. na ścieżkach 0x16).
- osm2mp.pl w etykietach dróg numerowanych używa ~[0x05]. W ulubionym edytorze tekstowym należy to zmienić na (najprawdopodobniej) ~[0x2f] (na przykład przy pomocy komendy
:%s/^Label=\~\[0x05\]/Label=\~[0x2f]/) - osm2mp.pl nie umieszcza w obiektach informacji o przynależności do miast. Na to niestety nie ma prostej rady - albo trzeba uzupełniać ręcznie, albo pozostawić na jakiś czas bez tych danych. W ME++ i opcji montowania mapy z --cityidx można łatwo zaznaczać całe obszary i przypisywać je do konkretnego miasta, pod awrunkiem że wiemy do jakiego oczywiście :)
Przed wczytaniem tak przygotowanej mapy roboczej warto zrobić jeszzce jedną rzecz – zmontować interesujący nas obszar i wygenerować jego zawartość w postaci pliku *.plt, aby mieć podkład porównawczy co w UMPie już jest. Na przykład:
cd tmp make mont diff -u /dev/null wynik.mp | ../narzedzia/pltdiff
Po czym powstały plik new.plt kopiujemy pod jakąś więcej mówiącą nazwę i dodajemy jako załącznik do roboczej wyczyszczonej mapy OSM, z której będziemy przenosić dane. (Analogicznie możemy sobie z mapy OSM zrobić plik PLT wczytany z obszarem UMP-a, by widzieć gdzie są dane w OSM na miejscach braków w UMP).
W końcu -- otwieramy 2 instancie Mapedita, w jednej plik roboczy z załącznikiem, w drugiej zmontowany obszar UMP, kopiujemy lub wycinamy dane z mapy roboczej, wklejamy do mapy UMP, co jakiś czas nagrywany i robimy rozmontowanie/kopia do src/zmontowanie na nowo. Warto kopiować kawałkami i rozmontowywać/montować, żeby przy okazji poprawiać błędy. Łatwiej też dzielić importowane dane na pliki, jeśli importujemy zarówno POI jak i drogi czy obszary.
Mimo wstępnego czyszczenia danych dokonanego wcześniej, w trakcie kopiowania i tak należy zwrócić uwagę na kilka rzeczy, które mogą wymagać poprawienia:
- poziomy widoczności ulic (naciskając 0, 1, 2, 3 i oglądając co znika oraz zwracając uwagę na to, czy pozostała siatka dróg jest spójna)
- przynależność do miast
- czy węzły nie są za blisko ("make close" bardzo pomaga)
- nazwy (imiona i inne)
- czy ulice nie kończą się o 1 punkt za skrzyżowaniem zamiast na skrzyżowaniu (częsta przypadłość OSM-a)
- ulice i inne dane adresowe w POI-ach
- czy mimo wcześniejszej generalizacji nie należy nadal uprościć niektórych rzeczy
- czy jednokierunkowe są dobrze zdefiniowane (szczególnie na rozrysowanych szczegółowo skrzyżowaniach)
- czy nie należałoby zmienić typów niektórych dróg (z reguły 0x4 vs 0x5)
Sposób z MapEdit++
Od kwietnia 2010 MapEdit++ ma możliwość importu i eksportu w formacie OSM, choć jest to dość żmudne zajęcie i nie jest polecaną metodą importu, gdyż gubi wszelkie informacje o typach dróg -- trzeba je później uzupełniać ręcznie..
Importujemy wybrany fragment OSM do pliku *.osm w podany wyżej sposób. Przy większych obszarach trzeba to zrobić w kilku kawałkach.
Uruchamiamy ME++, w zakładce "File" wybieramy "Import", a następnie "OpenStreetMap XML file". Po wybraniu pliku otwiera się okno importu. Zaznaczamy w nim "Import objects with unknown types" i "Join outer parts", a w "Save tags" wybieramy wariant "Place into fields". Następnie wybieramy do importu tylko Level 0 i klikamy "Zakończ". Powtarzamy ten import dla kolejnych kawałków. Na końcu wykonujemy operację "Remove object duplicates".
Zaimportowany fragment mapy zawiera wyłącznie obiekty typu 0x0. Do dalszej obróbki musimy podzielić go na trzy oddzielne pliki zawierające punkty, obszary i linie. Każdy z tych plików obrabiamy osobno korzystając naprzemiennie z edytora tekstowego i ME++.
Otwieramy zaimportowany plik w edytorze tekstowym. Obiekty z OSM mają wszystkie dane zapisane przez ME++ jako Extras, np. tak:
[POLYLINE] Type=0x0 Data0=(........... osm:id=31398313 way osm:highway=tertiary osm:lanes=3 osm:name=Novosmolenskaya Embankment osm:oneway=yes [END]
W dalszej pracy skorzystamy z trzech własności ME++:
1. umieszcza wpisy o znanych etykietach (np. Label, DirIndicator, Miasto itd.) we właściwej kolejności;
2. usuwa komentarze znajdujące się wewnątrz opisu obiektu (za słowem POLYLINE, POLYGON i POI);
3. w przypadku kilku identycznych etykiet wybiera ostatnią, np. z wpisu:
Label=A
Label=B
Label=C
po zapisaniu przez ME++ otrzymamy Label=C.
Otwieramy plik do obróbki ulubionym edytorem tekstowym.
Zbędne wpisy usuwamy zamieniając je na komentarze, np.: Global Replace - "osm:id=" > ";".
Właściwe parametry obiektów określamy także korzystając z Global Replace, np.:
"osm:highway=tertiary" > "Type=0x5"
"osm:name=" > "Label="
"osm:oneway=yes" > "DirIndicator=1"
Po kilkunastu zmianach trzeba plik zapisać, odczytać w ME++, zapisać w celu uporządkowania i ponownie odczytać w edytorze. I tak, aż do skutku. :)
UWAGI:
1. Ronda i place są często zapisywane w OSM jako obszary.
2. Odwrotnie, morza i duże jeziora są zapisywane jako linie typu "coastline", a rzeki zamiast obszarem typu 0x48 - linią typu "water" lub "river". Zdarza się to również w przypadku dużych lasów.
3. Obiekty w OSM mają dużo więcej atrybutów i typów niż w UMP. Trzy przykłady:
a) droga "osm:highway=residential" powinna być zamieniona na "Type=0x6", może mieć jednak dodatkowy parametr "osm:surface=unpaved" i trzeba zmienić jej typ na 0xa (ale nie globalnie, bo ścieżka piesza lub rowerowa też może być unpaved)
b) ścieżka może mieć atrybuty "osm:foot=yes", "osm:bicycle=no" itp. - aby je uwzględnić trzeba zmienić RouteParam
c) ścieżka typu 0x16 może mieć parametr "osm:highway=" określony jako foot, path, track i inne. Dotyczy to również innych obiektów.
4. Pracować uważnie - różne kwiatki się trafiają.
